We've looked into the use of large language models (LLMs) for generating synthetic text for NLP. We’ve improved the few-shot learning performance of GPT-3 6B by conditioning the GPT-3 model on a few input-output examples, and using it to generate new synthetic input-output examples, which can give the model more context. In addition, we’ve found that using synthetically generated text to distill the knowledge of a compute-intensive transformer into a compact transformer leads to state-of-the-art performance for efficient NLP models on the GLUE benchmark. We call our approach GAL: Generate, Annotate and Learn
Few-shot Learning with Synthetic Text
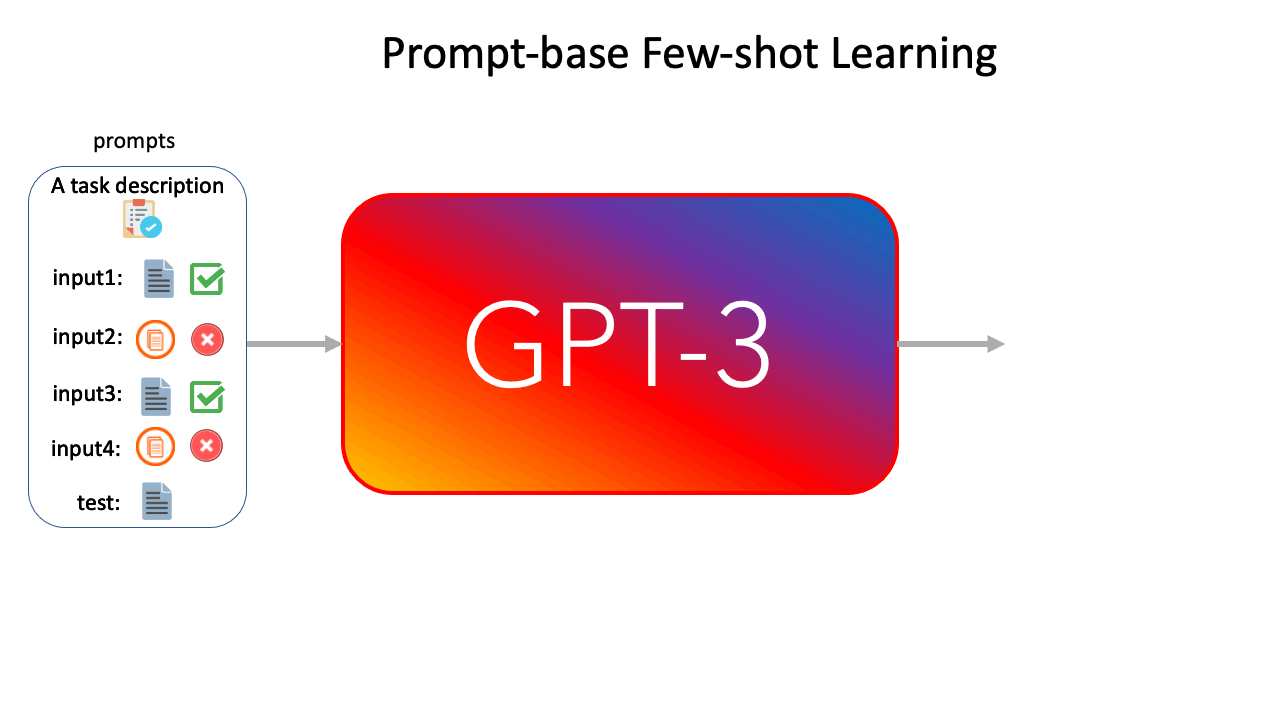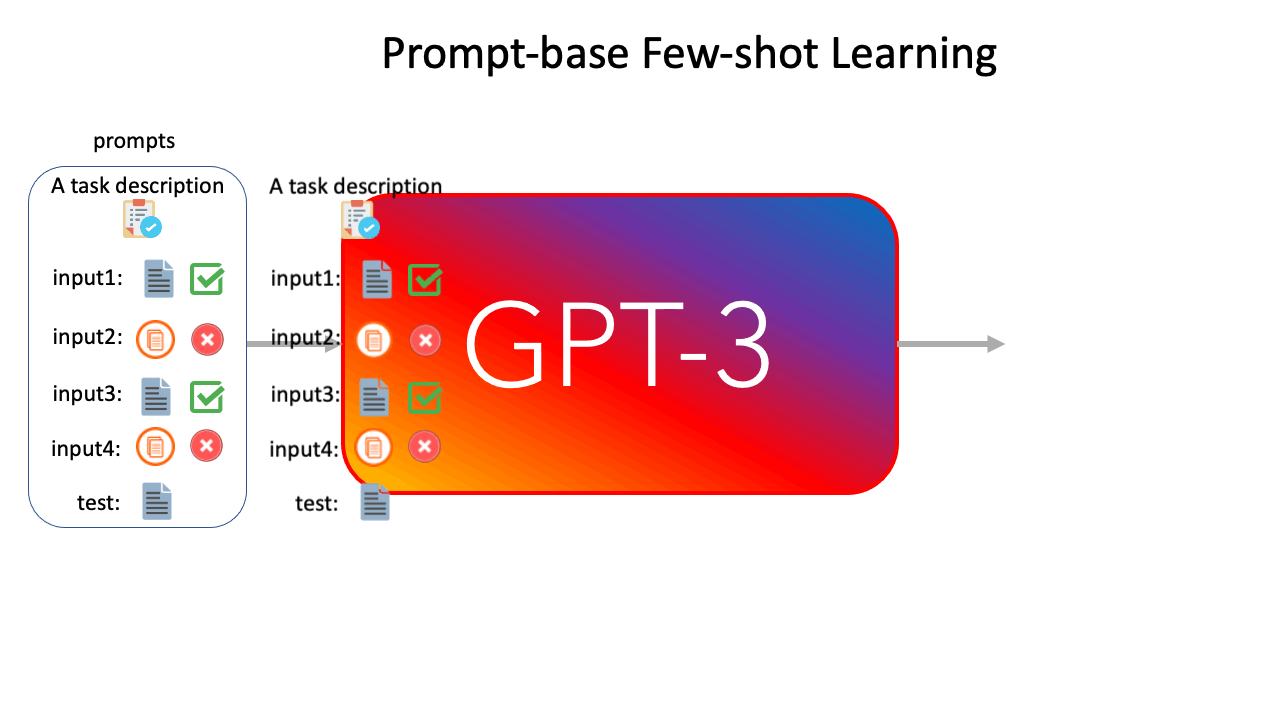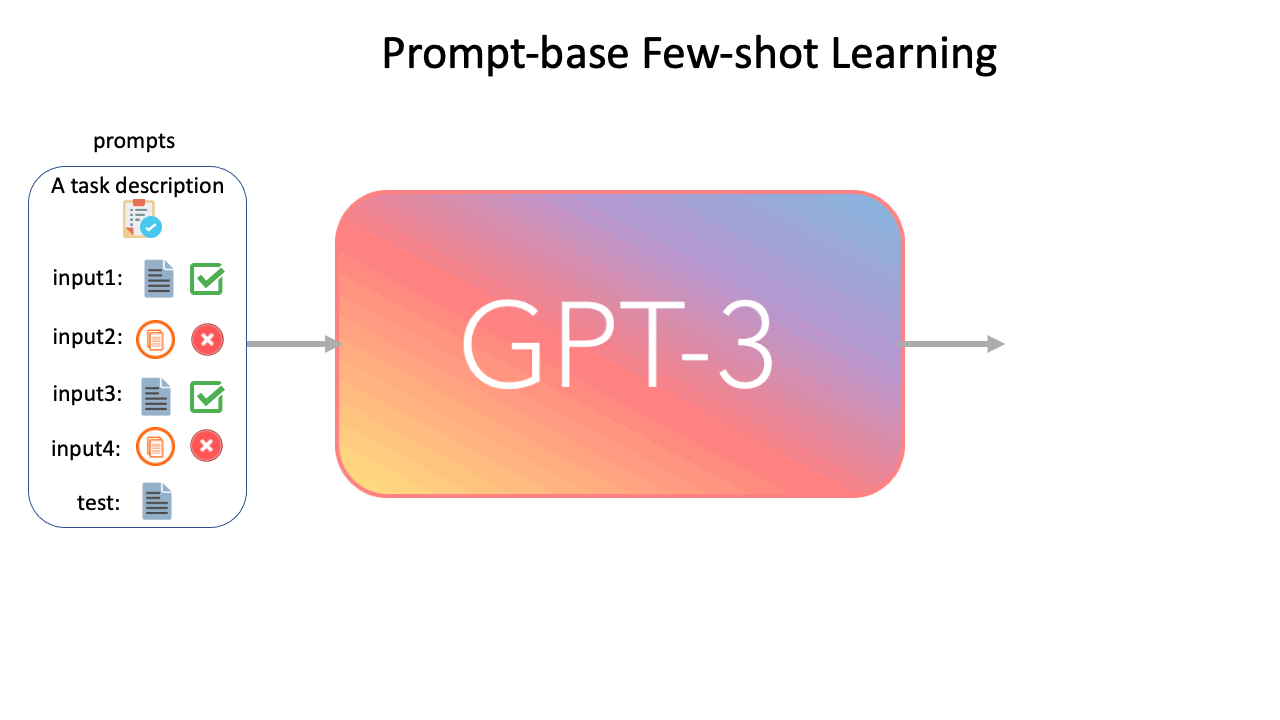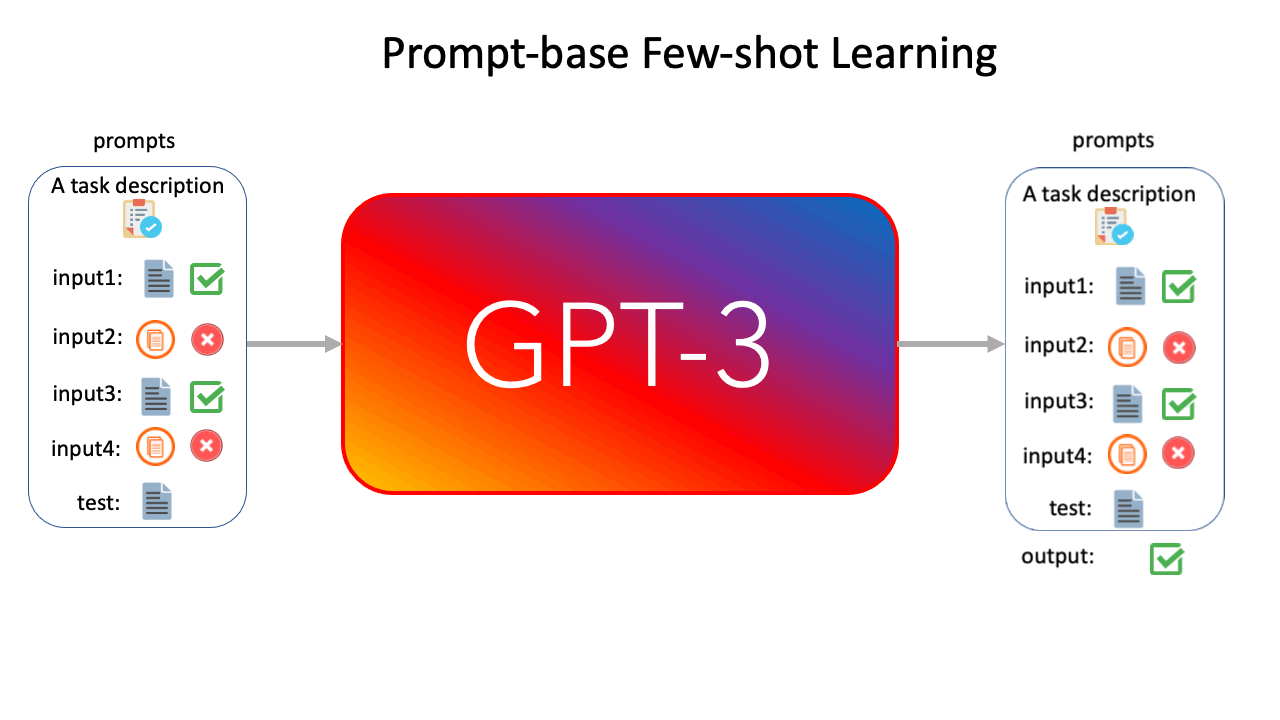
We first test our approach on few-shot learning with GPT-3 6B. GPT-3 proposed a novel approach to conduct few-shot learning. Specifically, as shown in Figure 1, one can craft a prompt consisting of instruction, a few labeled instances, and a new unlabeled text example. GPT-3 will complete the prompt by generating the corresponding label for the unlabeled instance.
Now, we apply GAL to prompt-based few-shot learning. According to Figure 2, we present k labeled examples as a prompt to GPT-3 6B, and generate m synthetic examples, followed by the corresponding labels. Note that to mitigate noisy outputs, the generation of each synthetic example only conditions on the original k labeled examples. Finally, we concatenate the original k examples and m synthetic examples, and conduct a (k+m)-shot learning experiment with GPT-3 6B.
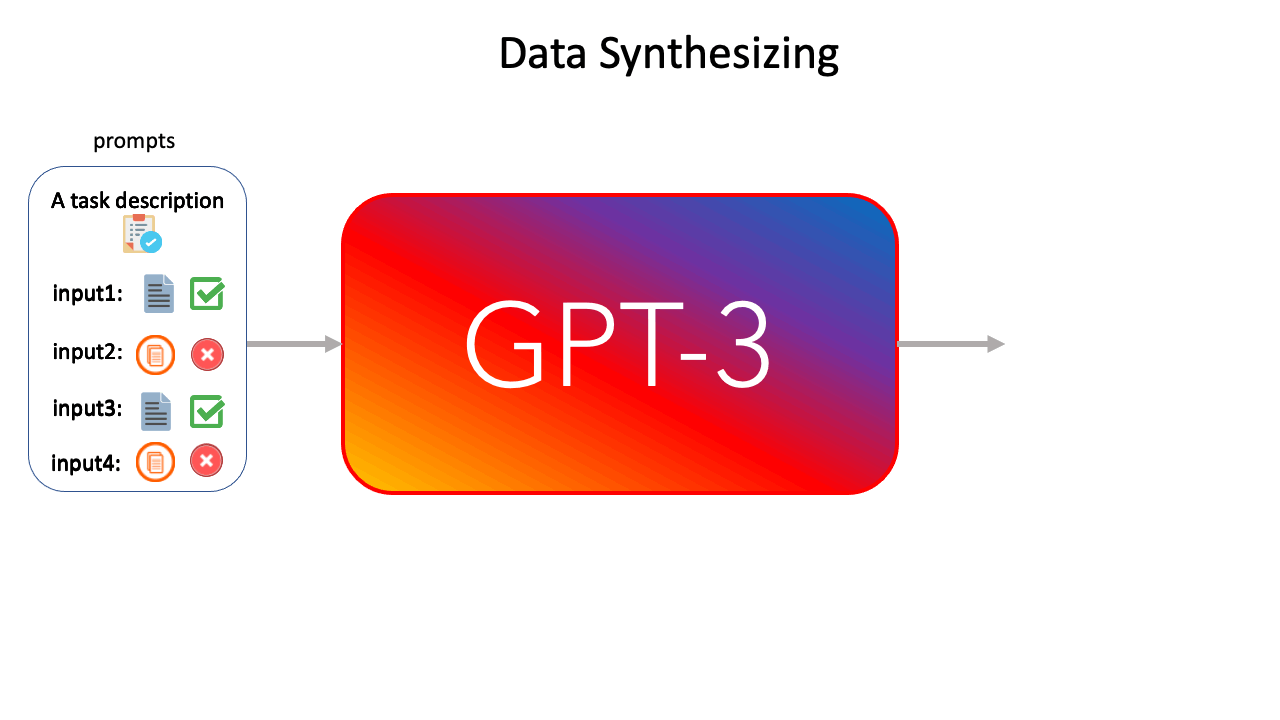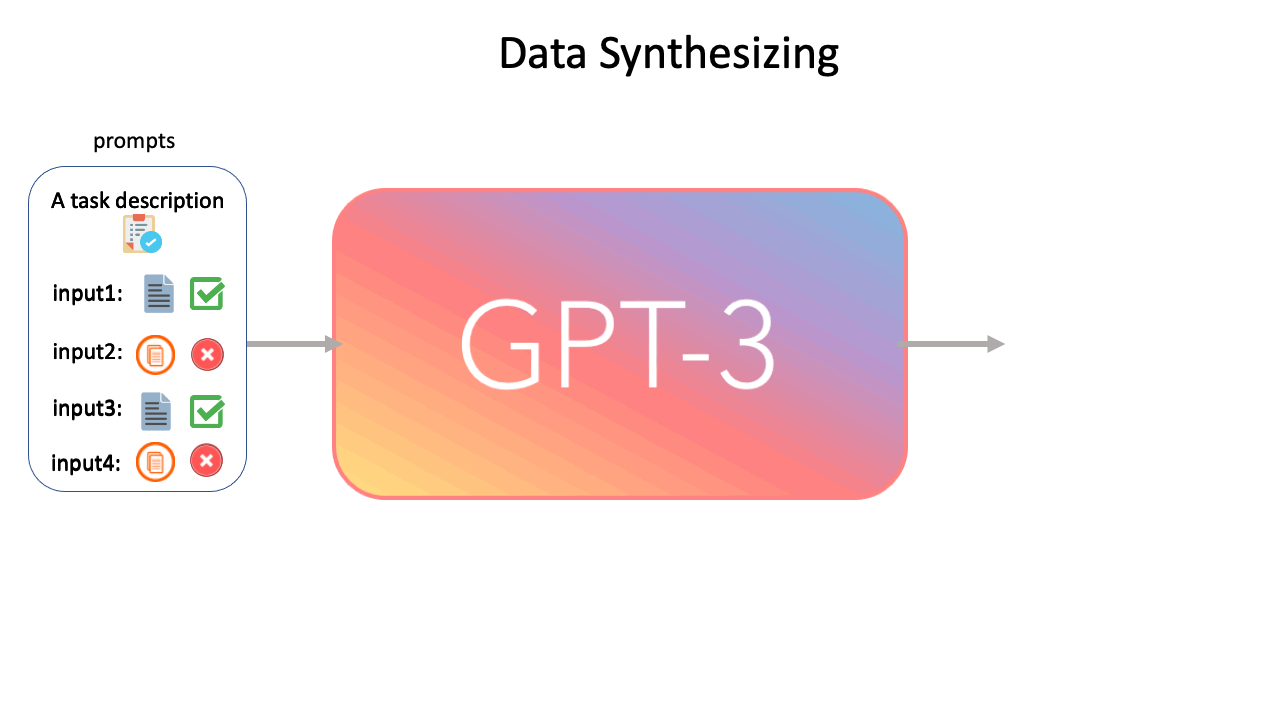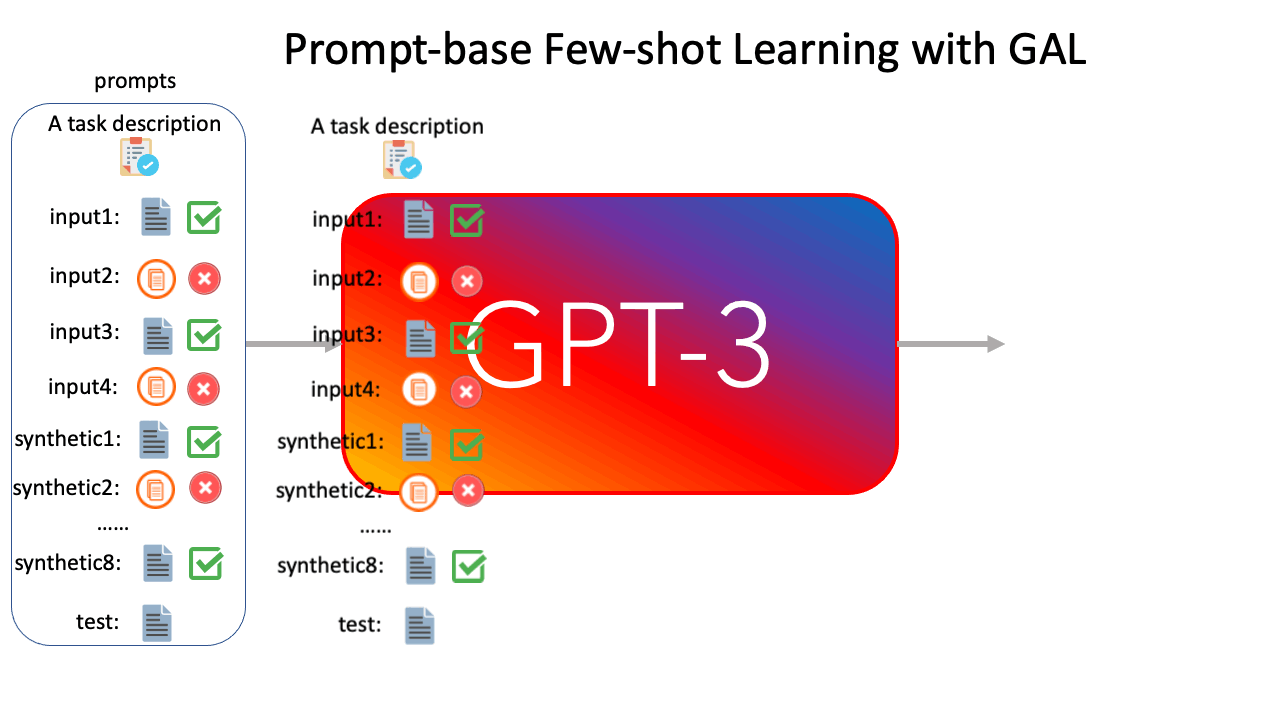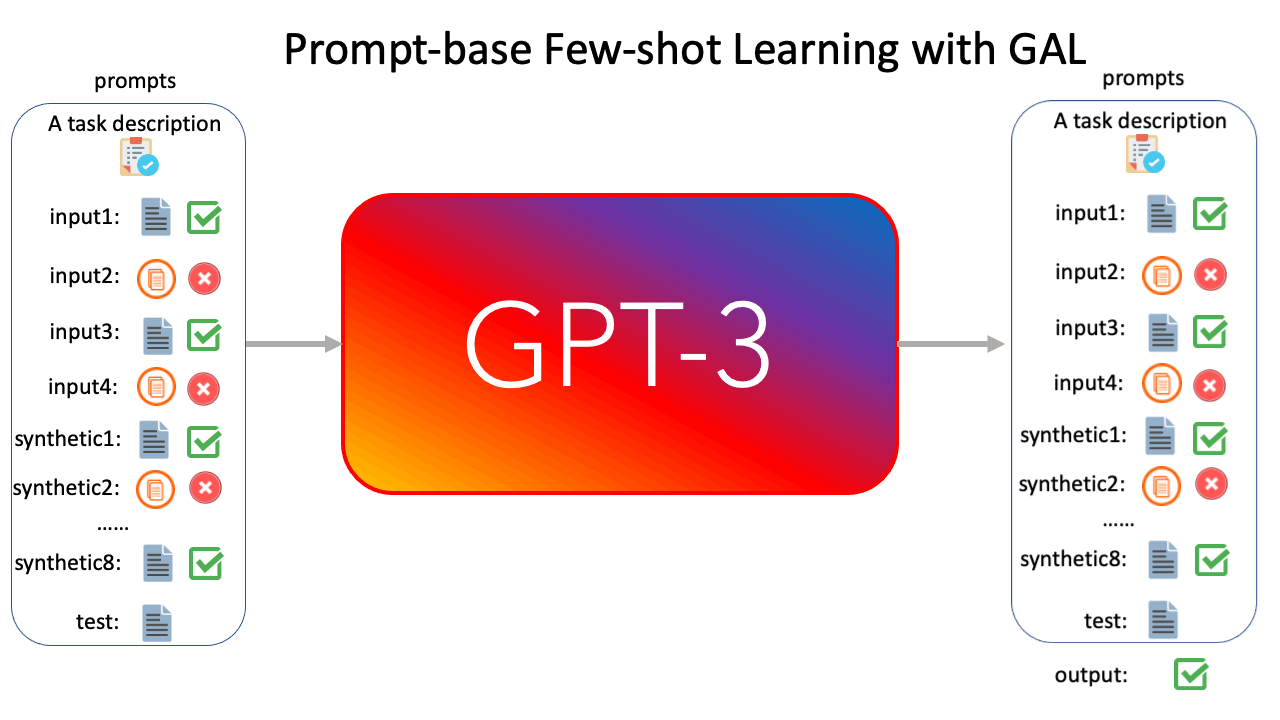
Figure 3 shows that GAL can significantly improve the few-shot learning results by generating more synthetic labeled examples.

Knowledge Distillation with Synthetic Text
There is an abundance of unlabeled data in the real world, but task-specific unlabeled data can be challenging to find. For instance, one cannot find in-domain unlabeled text conforming to the input distribution of a specific NLP task from the GLUE benchmark. Some NLP tasks require an input comprising a pair of sentences with a particular relationship. If task-specific unlabeled data were available, we could use them knowledge distillation. To fill in this gap, we consider using LLMs as a means of data synthesizer. As shown in Figure 4, we first finetune a GPT2
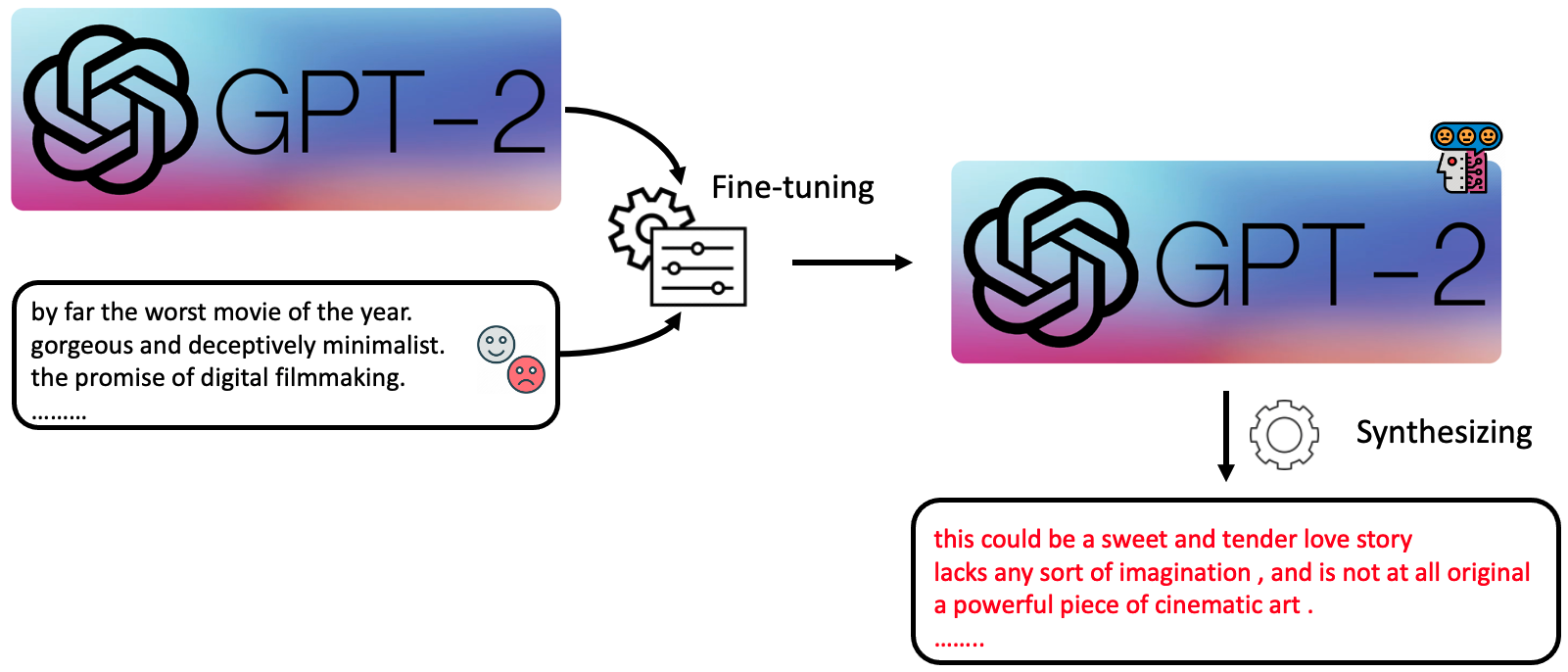
We first train a teacher model from the labeled training data. Then we can annotate the unlabeled data with the aid of the teacher model. Eventually, we can compress the knowledge of the teacher model into a compact student model via the original training data and pseudo-labeled synthetic data.
We compare GAL with the following baselines: BERT-Theseus

GAL for Other Classification Tasks
To demonstrate the universality of GAL, we also employ it for tabular and image classification tasks. According to Figure 6 and 7, GAL is effective on tabular and image classification tasks as well.


Synthetic Examples
We provide some synthetic images and text generated by our approach below. Please refer to our paper for more examples.
Synthetic Images

Synthetic Text

Citation
For more details and additional results, read the full paper.
@article{he2021generate,
title={Generate, annotate, and learn: Generative models advance self-training and knowledge distillation},
author={He, Xuanli and Nassar, Islam and Kiros, Jamie and Haffari, Gholamreza and Norouzi, Mohammad},
journal={arXiv:2106.06168},
year={2021}}
}